
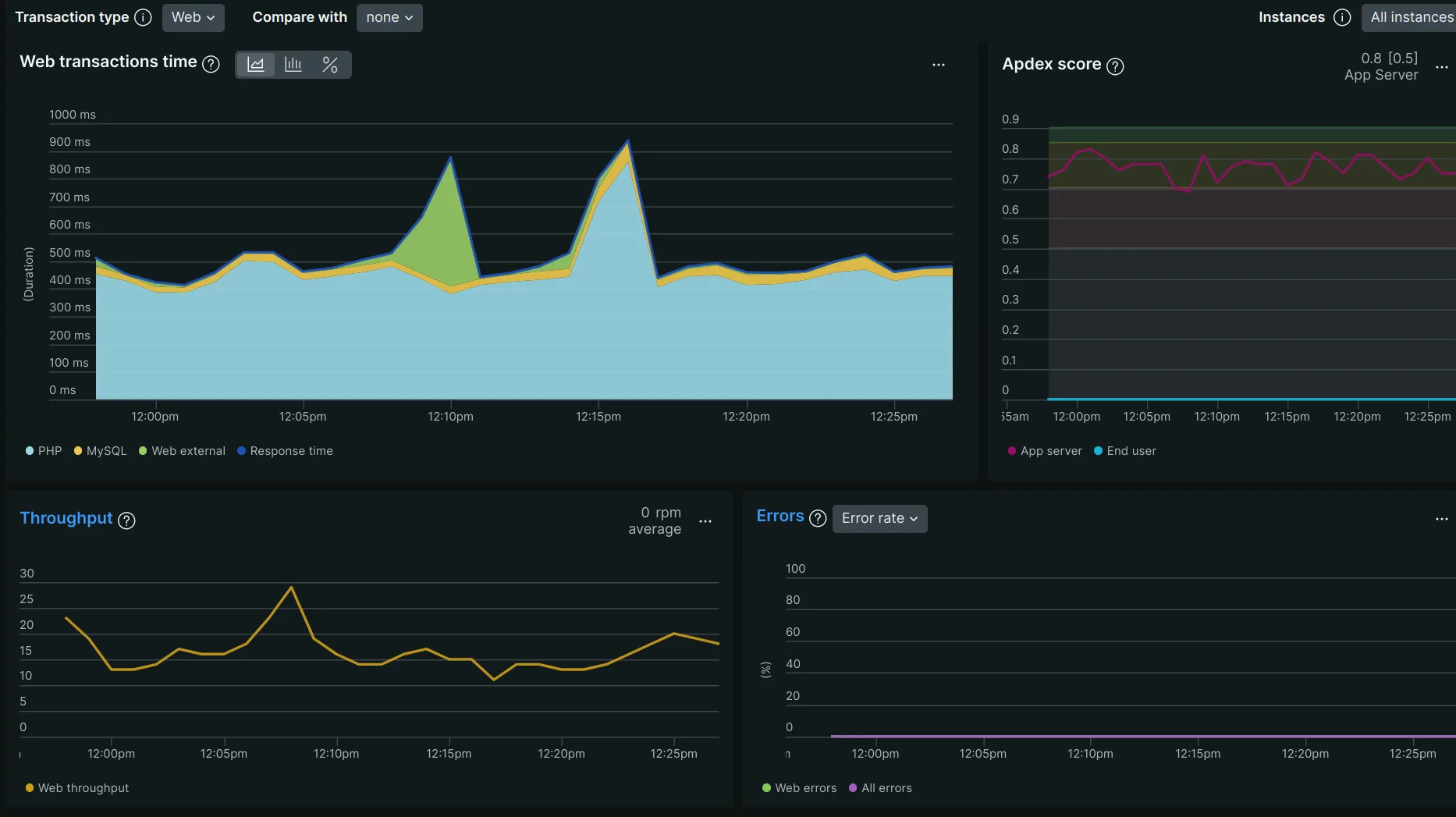
Ever had that moment where you’re casually scrolling through New Relic on a quiet afternoon, and something makes you do a double-take? That’s what happened when I spotted a 100ms JSON parse hanging out in our production traces. Now, 100 milliseconds might not sound like much – it’s about how long it takes to blink – but when you’re processing thousands of requests, those blinks add up fast.
The culprit? A seemingly innocent JSON encoding function that turned out to be doing way more work than necessary. Let’s dive into what made this particular piece of code interesting, and more importantly, how we fixed it.
Finding the First Clue
Looking closer at the New Relic trace, something interesting emerged. The slow function was named
jsonEncodeUTFnormalWpf()
– living inside a popular WooCommerce filtering plugin. At first glance, JSON encoding shouldn’t take 100ms. But this wasn’t just any JSON encoder.
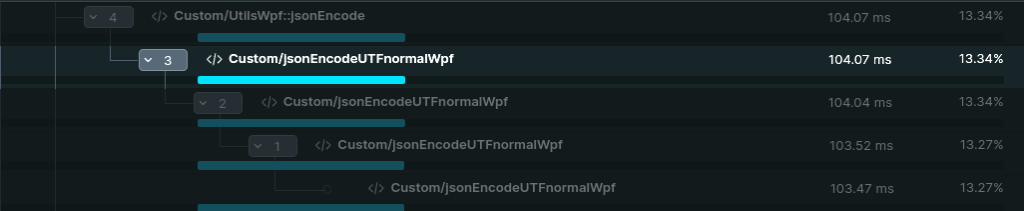
The trace revealed something fascinating – this wasn’t just a slow function, but a glimpse into WordPress’s past. The function was calling itself repeatedly, like nested Russian dolls, each call meticulously processing data character by character. But why was it written this way?
The answer lies in the function’s name: jsonEncodeUTFnormalWpf. The ‘UTFnormal’ part tells us this code emerged during WordPress’s early struggles with character encoding, around 2006-2007. This was a pivotal time in web development when PHP’s handling of non-English characters was still maturing.
To understand why a developer would write such complex code, we need to look at PHP’s JSON journey. When this function was written, PHP had just introduced json_encode() in version 5.2.0 (2006), but these early implementations were far from complete. If you needed to handle non-English characters reliably, you faced significant challenges:
Prior to PHP 5.3.0 (2009), any Unicode character would be automatically escaped into \uXXXX sequences – making the JSON output difficult to read and work with. Developers had to manually handle character encoding to maintain readability. It wasn’t until PHP 5.4.0 (2012) that the JSON_UNESCAPED_UNICODE flag arrived, finally offering a clean solution for UTF-8 output.
The challenges didn’t stop there. Handling malformed UTF-8 data, common in early WordPress installations, remained problematic until PHP 5.5.0 (2013) introduced JSON_PARTIAL_OUTPUT_ON_ERROR. And it took until PHP 7.2 (2017) before we got JSON_INVALID_UTF8_SUBSTITUTE, which finally provided a robust way to handle invalid character encodings.
This historical context explains the seemingly unnecessary complexity in our function. The unused $convmap array and the painstaking character-by-character processing weren’t over-engineering – they were essential workarounds for PHP’s limitations at the time. In 2006, if you needed reliable JSON encoding with proper UTF-8 support across different WordPress configurations, you had to build it yourself.
What we were seeing in the trace wasn’t just a performance problem – it was a snapshot of WordPress history, a piece of code that had survived long past the technical limitations it was designed to overcome.
Analyzing the Original Code
Let’s look at the original function we found in the plugin:
function jsonEncodeUTFnormalWpf($value) {
if (is_int($value)) {
return (string) $value;
} elseif (is_string($value)) {
// First, replace all special characters
$value = str_replace(array('\\', '/', '"', "\r", "\n", "\b", "\f", "\t"),
array('\\\\', '\/', '\"', '\r', '\n', '\b', '\f', '\t'), $value);
// Unused UTF-8 conversion map
$convmap = array(0x80, 0xFFFF, 0, 0xFFFF);
$result = '';
// Reverse iterate through the string character by character
for ($i = strlen($value) - 1; $i >= 0; $i--) {
$mb_char = substr($value, $i, 1);
$result = $mb_char . $result;
}
return '"' . $result . '"';
}
// ... rest of the functionThe most interesting part is how it handles strings. For every string value, even something as simple as “product”, the function:
- Performs a str_replace() with 8 different pattern replacements
- Creates an unused UTF-8 conversion map (likely a remnant of old character encoding handling)
- Reverses the string character by character using an inefficient method:
- Gets the string length
- Iterates backwards
- Extracts each character individually using substr()
- Concatenates characters one at a time
For arrays, it gets even more complex:
} elseif (is_array($value)) {
$with_keys = false;
$n = count($value);
// First loop: check if array is associative
for ($i = 0, reset($value); $i < $n; $i++, next($value)) {
if (key($value) !== $i) {
$with_keys = true;
break;
}
}The function manually iterates through arrays to determine if they’re associative, using PHP’s old-style array pointer functions (reset() and next()). Then it makes another pass through the array to actually encode the values, recursively calling itself for each element.
Performance Implications
To understand why this code is problematic, let’s track what happens when it processes the example product data. The seemingly simple task of JSON encoding becomes a cascade of expensive operations.
When encoding our product data:
$product = [
'name' => 'T-shirt',
'variants' => [
['size' => 'S', 'color' => 'blue'],
['size' => 'M', 'color' => 'red']
]
];First, it iterates through the given array, checking every key to determine the array type. In the best case, we will hit a key value not equal to i on the first element and break, but in the worst case, this singular check has a time complexity of O(n). Potentially, we have already iterated through the entire array once.
Then comes the actual encoding process. Take a simple entry like the product name. For this one field, we trigger:
if ($with_keys) {
foreach ($value as $key => $v) {
$result[] = jsonEncodeUTFnormalWpf((string) $key) . ':' . jsonEncodeUTFnormalWpf($v);
}
return '{' . implode(',', $result) . '}';
} else {
foreach ($value as $key => $v) {
$result[] = jsonEncodeUTFnormalWpf($v);
}
return '[' . implode(',', $result) . ']';
}- A recursive call to encode the “name” key
- Another recursive call to encode the “T-shirt” value
The string handling is particularly inefficient. When processing “T-shirt”, the function:
- Makes a complete copy of the string
- Runs 8 different pattern checks against every character
- Reverses the entire string character by character using individual substr() calls
- Rebuilds the string from these individual characters
The real cost multiplies when we hit the variants array. The function repeats this entire process for each nested array, each key, and each value. Every string goes through the same expensive character-by-character processing.
What makes this especially costly in PHP is memory handling. String operations create new memory allocations, and our function is creating new strings constantly. With each recursive call and string operation, we’re not just using CPU cycles – we’re fragmenting memory and forcing PHP to manage more and more small allocations.
This explains our 100ms processing time. We’re not simply encoding JSON – we’re performing layers of unnecessary work:
- Multiple passes over our data structure
- Redundant string copying and character checks
- Constant memory allocation and deallocation
- Recursive function calls at every level
- Character-by-character string manipulation
This approach might have made sense in 2006 when PHP’s JSON and UTF-8 handling was less reliable, but today it’s solving problems that no longer exist.
The Solution: Sometimes Simpler is Better
After all our investigation into this complex piece of legacy code, the solution turned out to be surprisingly simple. Modern PHP already has all the tools we need to handle JSON encoding correctly, including proper UTF-8 support:
function jsonEncodeUTFnormalWpf($value) {
return json_encode($value,
JSON_UNESCAPED_UNICODE | // Handle UTF-8 characters properly
JSON_PARTIAL_OUTPUT_ON_ERROR | // Don't fail on single bad value
JSON_INVALID_UTF8_SUBSTITUTE // Replace invalid encodings
) ?: ''; // Maintain original empty string fallback
}That’s it. Three lines of code replaced the entire recursive implementation. The flags we chose are important:
-
JSON_UNESCAPED_UNICODEensures proper handling of non-Latin characters -
JSON_PARTIAL_OUTPUT_ON_ERRORmaintains the original function’s forgiving nature -
JSON_INVALID_UTF8_SUBSTITUTEsafely handles any malformed UTF-8 sequences
The performance impact was dramatic. Our 100ms processing time dropped to consistently under 1ms. Memory usage plummeted since we’re no longer creating temporary strings and arrays. Best of all, we maintained complete compatibility with the original function’s behavior.
Benchmark Results
During my investigation, I attempted to locate the optimized function within the New Relic stack trace for comparison with the legacy implementation. Unable to find the precise trace, I developed a custom benchmark to quantify the performance differences between the old and new versions of the function.
Legacy Implementation:
Time: 0.993 ms
Memory: 0.00 bytes
Modern Implementation:
Time: 0.007 ms
Memory: 0.00 bytesThis represents approximately a 141x speed improvement (0.993 ms ÷ 0.007 ms ≈ 141), which is quite good for such a long running task.
The source code for the benchmark can be found on our GitHub
Broader Lessons: What Legacy Code Can Teach Us
This journey from complex legacy code to a simple modern solution teaches us several valuable lessons about WordPress development:
First, always understand the historical context. Our legacy function wasn’t poorly written – it was solving real problems that existed in 2006. Understanding why code was written a certain way helps us make better decisions about how to modernize it.
Second, performance problems often hide in plain sight. This function had likely been running slowly for years, but because JSON encoding is such a basic operation, nobody thought to question its performance. The most expensive operations are sometimes the ones we take for granted.
Third, modern PHP provides solutions to many historical problems. Features we had to code around in the past – like UTF-8 handling and JSON encoding – are now robust parts of the language. Before writing complex workarounds, check if the problem has already been solved.
Finally, when modernizing legacy code, maintain its contract with the outside world. Our new implementation produces the same output format and handles edge cases the same way as the original. This allows for safe upgrades without breaking dependent code.
These lessons apply well beyond JSON encoding. Many WordPress plugins and themes contain similar historical artifacts – complex solutions to problems that PHP now handles natively. Finding and modernizing these patterns can lead to significant performance improvements across your WordPress sites.
Closing Thoughts
What started as a performance investigation led us to a broader lesson about WordPress development. Our slow JSON encoder wasn’t just inefficient – it was a snapshot of WordPress history, showing how developers once had to work around PHP’s limitations.
The key insight wasn’t about JSON or even performance – it was about understanding our tools. Modern PHP has evolved tremendously, yet many WordPress codebases still carry solutions to problems that no longer exist. What made sense in 2006 might be unnecessarily complex in 2024.
Sometimes the best optimization isn’t adding more code – it’s recognizing when we can remove it, replacing complex workarounds with modern, built-in solutions. This requires us to look at old code with fresh eyes while being mindful of maintaining compatibility.
After all, a deep understanding of how our tools have evolved helps us write better, more efficient code for the future.


Skriv et svar